Powerful experiments.
AI-ready data. Ever faster discovery.
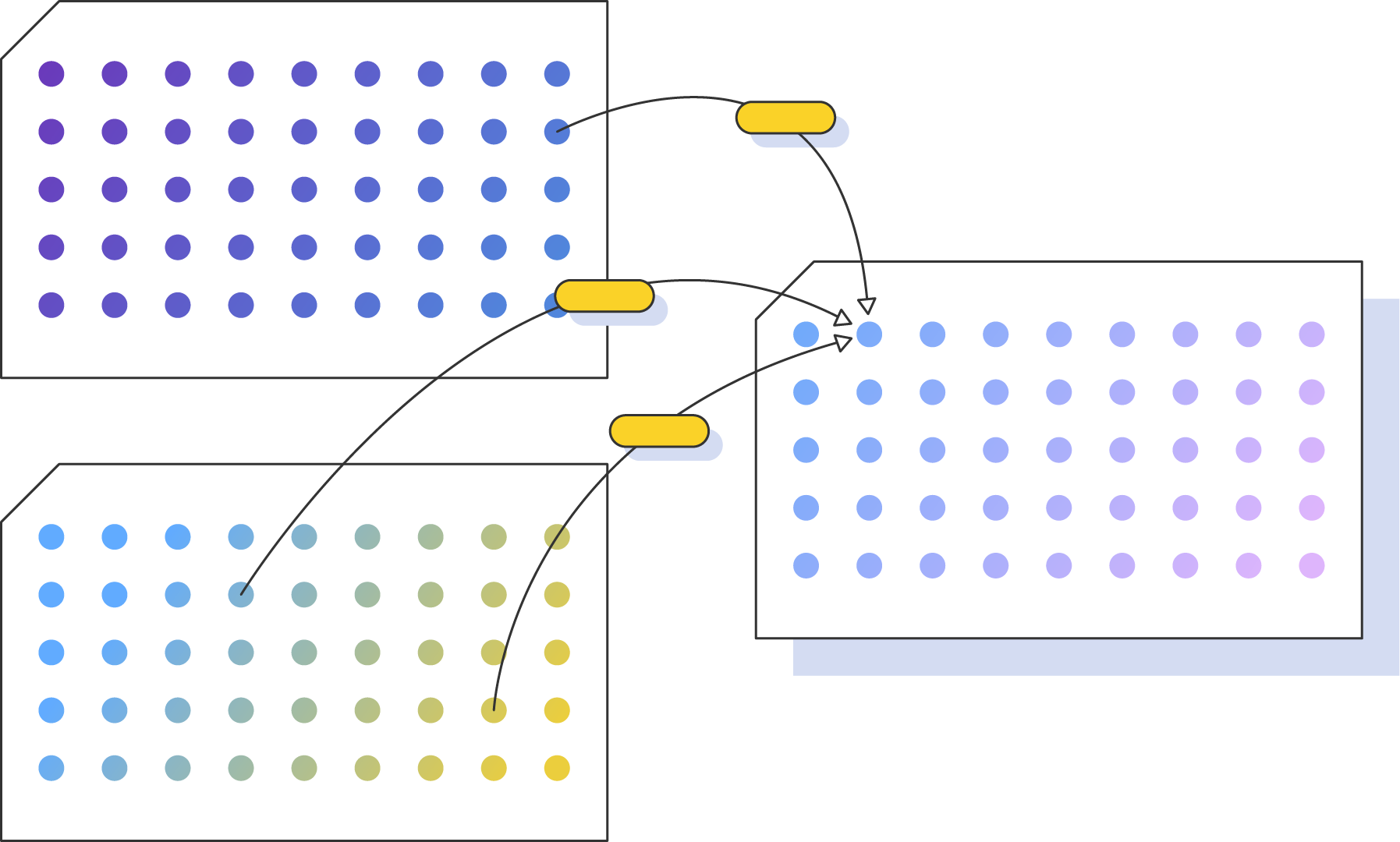
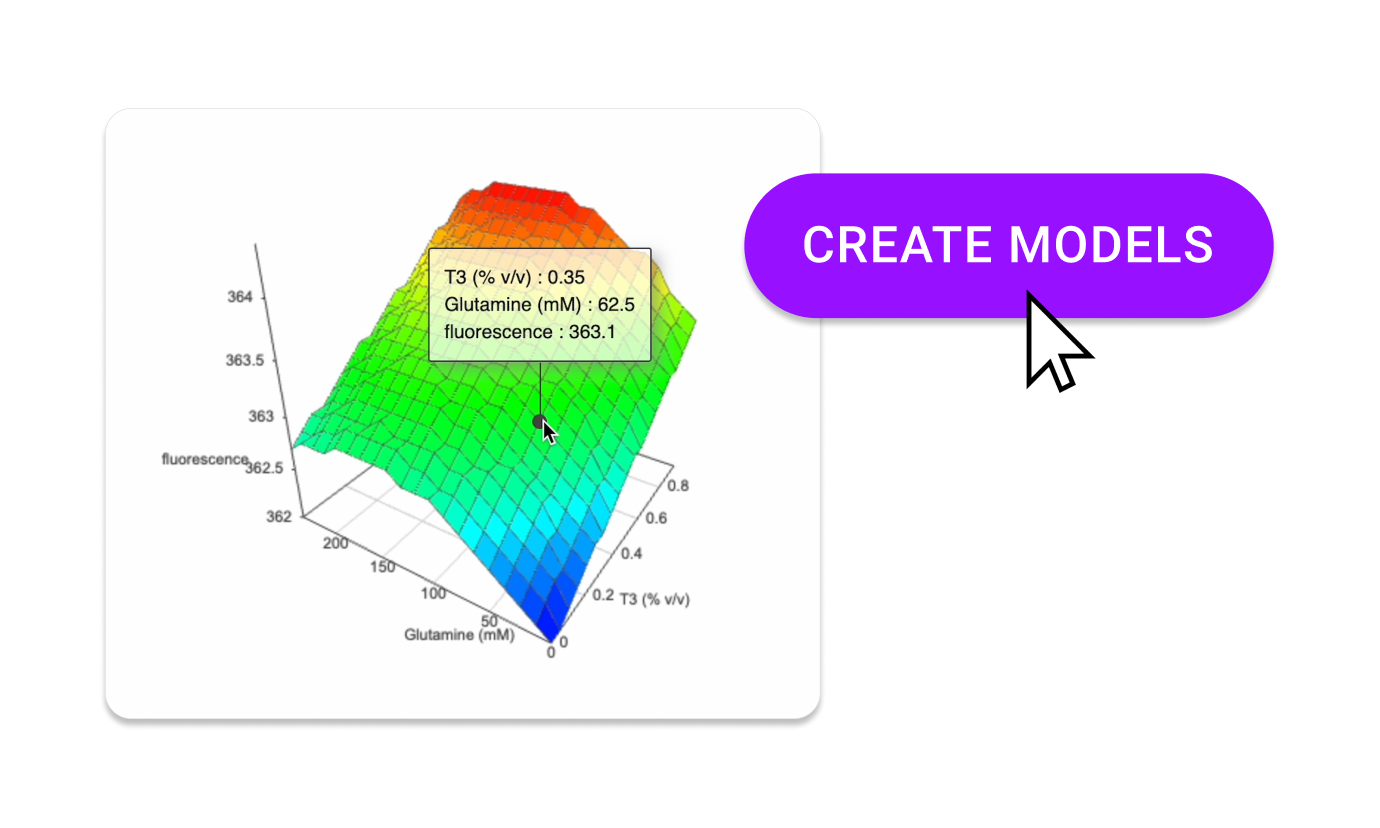
Remove the friction from discovery biology. Design, automate, and run powerful experiments, and generate high dimensional, fully contextualized datasets for AI.
Request a demo

The problem
Drug discovery needs AI. But AI demands high dimensional data.

- Traditional experimental approaches miss the deep biological insights that only high dimensional data delivers.
- Under constant pressure to hit milestones, the cost of adapting rigid automation or manual processes makes switching to smarter methods feel impossible.
- Data is messy and stripped of context. Scientists waste weeks manually cleaning and aligning fragmented results that aren't structured for modern analysis.
.png)
DEDICATED SPECIALISTS
Keep control of projects, from start to finish.
Our specialists become extended members of your in-house discovery teams. They lend your scientists our decades of experience, and your scientists run the experiments.